
كل ما تحتاج معرفته عن نموذج LLaMA 3.1 405B من ميتا
نموذج Llama 3.1: قفزة نوعية في عالم الذكاء الاصطناعي مفتوح المصدر
في 23 يوليو 2024، أطلقت شركة ميتا نموذجها الجديد LLaMA 3.1 405B، والذي يُعتبر أكبر وأقوى نموذج مفتوح المصدر في مجال الذكاء الاصطناعي حتى الآن. يتضمن هذا النموذج تحسينات كبيرة في الأداء ويدعم مجموعة واسعة من التطبيقات العملية.
في هذه المقالة، سنستعرض تفاصيل هذا النموذج الثوري، بما في ذلك خصائصه، أدائه، تطبيقاته، وتوقعات مستقبلية.
ما هو نموذج LLaMA 3.1؟
نموذج LLaMA 3.1 هو مجموعة من النماذج اللغوية الكبيرة (LLMs) التي تم تصميمها لتوليد النصوص وفهمها. يتكون النموذج من ثلاثة أحجام مختلفة، بما في ذلك النسخة الأكثر تطورًا التي تحتوي على 405 مليار معلمة. تم تدريب هذا الإصدار باستخدام أكثر من 16,000 وحدة معالجة رسومية من نوع Nvidia H100، مما يجعله نموذجًا معقدًا للغاية.
لماذا يعتبر LLaMA 3.1 نموذجًا مبتكرًا؟
ما يجعل LLaMA 3.1 فريدًا هو أنه نموذج مفتوح المصدر، مما يعني أنه يمكن لأي شخص استخدامه وتعديله. إليك بعض الأسباب التي تجعله مهمًا:
- أداء متميز: حقق هذا النموذج نتائج رائعة في اختبارات الأداء، متفوقًا على العديد من النماذج الأخرى.
- تكلفة تشغيل منخفضة: يُعتبر LLaMA 3.1 خيارًا اقتصاديًا مقارنة بنماذج مثل GPT-4، مما يجعله جذابًا للمؤسسات والشركات.
- سهولة الاستخدام: يمكن للمطورين استخدامه في تطبيقاتهم الخاصة بسهولة.
لماذا تختار ميتا نهج مفتوح المصدر؟
قد يتساءل البعض عن سبب إصرار ميتا على تقديم Llama كمصدر مفتوح رغم التكلفة الباهظة لتطويره، حيث قُدّرت تكلفة شرائح نفيديا المُستخدمة للتدريب بمئات الملايين من الدولارات.
يجيب زوكربيرج على ذلك بأن نماذج الذكاء الاصطناعي مفتوحة المصدر ستتفوق على النماذج الخاصة في النهاية، تمامًا كما حدث مع نظام التشغيل لينكس الذي أصبح النظام الأكثر استخدامًا في الهواتف والخوادم والأجهزة اليوم.
علاوة على ذلك، يرى زوكربيرج أن مبادرة LLaMA تُشبه مشروع Open Compute الذي أطلقته ميتا سابقًا، والذي وفّر للشركة مليارات الدولارات من خلال السماح للشركات الأخرى بالمساهمة في تحسين وتوحيد تصاميم مراكز البيانات.
كيف يختلف LLaMA 3.1 عن النماذج السابقة؟
يُظهر LLaMA 3.1 عدة تحسينات مقارنة بالنماذج السابقة مثل LLaMA 2، بما في ذلك:
- زيادة عدد المعلمات: الإصدار الجديد يحتوي على 405 مليار معلمة، مما يعزز من قدرته على التعلم والتكيف.
- طول السياق: تمت زيادة طول السياق من 8,192 توكن إلى 128,000 توكن، مما يتيح للنموذج التعامل مع محادثات أطول دون فقدان التفاصيل.
- دعم لغات متعددة: يدعم LLaMA 3.1 عدة لغات، بما في ذلك الإنجليزية، الإسبانية، الألمانية، وغيرها.
الأداء والمعايير
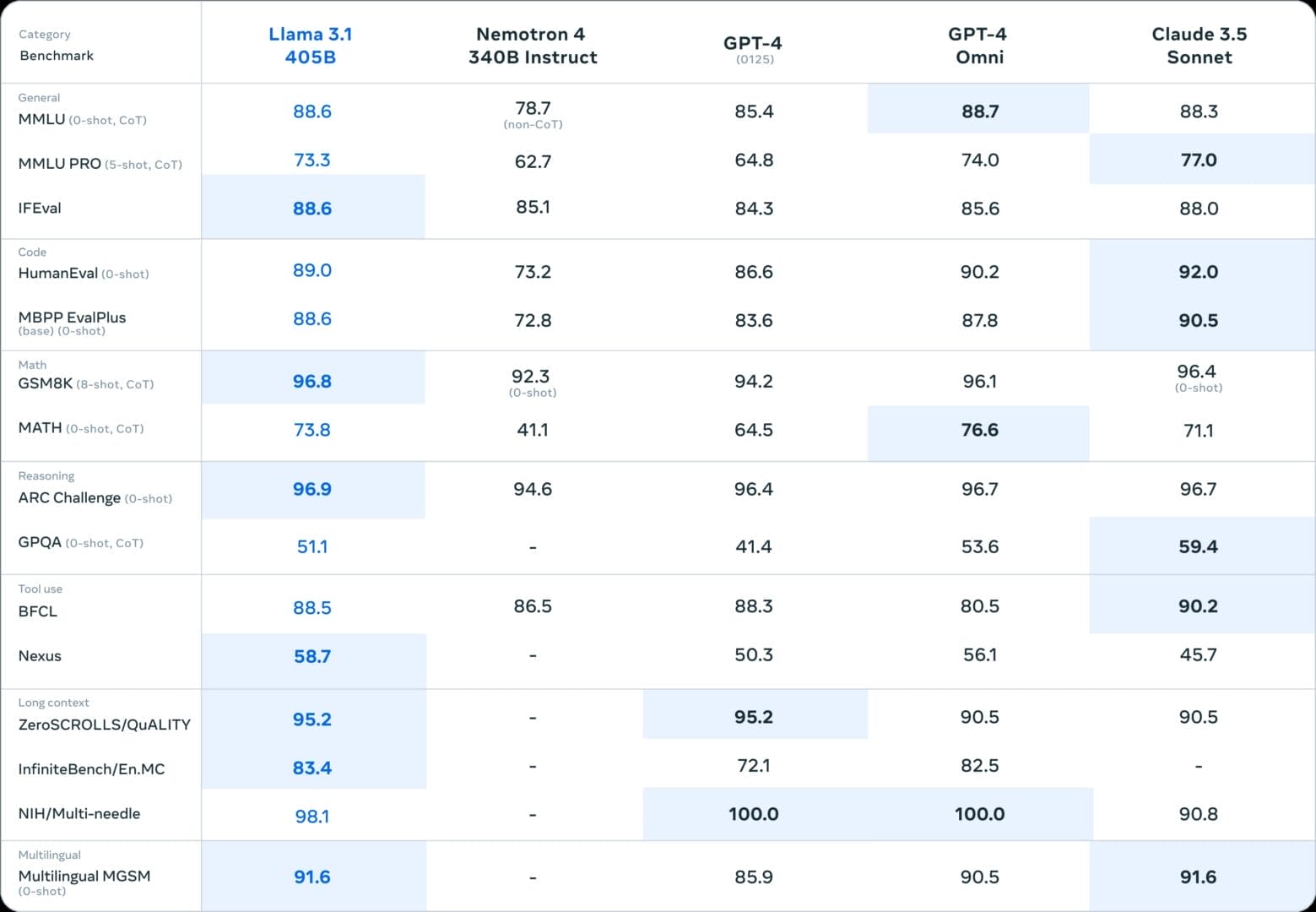
أظهرت الاختبارات التي أجرتها ميتا على 3.1-405B نتائجًا مذهلةً تُثبت قدرة النموذج على منافسة أقوى النماذج المتاحة حاليًا. على سبيل المثال:
- التفوق في اختبارات المعرفة الأكاديمية MMLU: حيث حقق 87.3% .مما يجعله متفوقًا على GPT-4-Turbo و Claude 3 Opus.
- حصل على 50.7% في اختبار GPQA، مما يدل على قدرته على التفكير المنطقي.
- في حل المشكلات الرياضية، أظهر النموذج كفاءةً عاليةً في حل المسائل الرياضية، حيث حصل على 73.8٪ في اختبار MATH، متفوقًا على جميع النماذج باستثناء GPT-4o.
- فهم استثنائي للنصوص: أثبت هذا الإصدار قدرةً فائقةً على فهم النصوص وذلك من خلال تحقيقه نتيجة 84.8 في اختبار DROP، متفوقًا على GPT-4o و Claude 3 Opus.
تُظهر هذه النتائج أن LLaMA 3.1 ليس فقط نموذجًا قويًا، بل يُمكن الاعتماد عليه في مجموعة متنوعة من التطبيقات.
اقرأ أيضا: مقارنة بين نماذج الذكاء الاصطناعي في مهام حل الألغاز الرياضية
التطبيقات العملية لنموذج LLaMA 3.1
يمكن استخدام نموذج LLaMA 3.1 في مجموعة واسعة من التطبيقات، تشمل:
- تطوير المساعدات الذكية: يمكن استخدام النموذج في تطوير مساعدات ذكية تعمل على تحسين تجربة المستخدم.
- توليد المحتوى: يمكن للنموذج توليد نصوص إبداعية، مقالات، أو حتى نصوص أكاديمية.
- تحليل البيانات: يمكن استخدامه لتحليل مجموعات كبيرة من البيانات واستخراج الأنماط.
التحديات والفرص
على الرغم من كل هذه المزايا، إلا أن هناك بعض التحديات التي يجب مراعاتها:
- الأمان والخصوصية: يجب على المطورين الحرص على حماية البيانات وخصوصيتها.
- التحيزات في البيانات: يمكن أن تؤثر البيانات المستخدمة في تدريب النموذج على نتائجه، لذا يجب التأكد من تنوع البيانات.
ومع ذلك، فإن الفرص التي يوفرها هذا الإصدار كبيرة، خاصة في مجالات مثل التعليم والتجارة الإلكترونية، حيث يمكن أن يُحدث LLaMA 3.1 فرقًا حقيقيًا.
الشراكات والدعم
تعمل ميتا مع العديد من الشركات الكبرى مثل مايكروسوفت، أمازون، وجوجل لدعم تطوير نموذج لاما 3.1. هذه الشراكات تعزز من قدرة النموذج على الانتشار وتقديم الدعم للمطورين في جميع أنحاء العالم.
توقعات مستقبلية
يتوقع مارك زوكربيرغ أن يتجاوز استخدام المساعد الذكي الخاص بميتا استخدام ChatGPT في الأشهر القادمة. كما يتوقع أن يُحدث LLaMA 3.1 ثورة في كيفية استخدام الذكاء الاصطناعي في حياتنا اليومية، مما يعزز من الابتكار في هذا المجال.
بالختام، فإن إطلاق LLaMA 3.1 من ميتا يمثل خطوة كبيرة نحو مستقبل أكثر إشراقًا في مجال الذكاء الاصطناعي. من خلال تقديم نموذج مفتوح المصدر يتيح للمطورين الابتكار بحرية، يمكن أن يُحدث هذا الإصدار ثورة في كيفية استخدام الذكاء الاصطناعي في حياتنا اليومية. إن التقدم في الأداء، والتطبيقات المتعددة، والدعم العالمي يجعل من LLaMA 3.1 نموذجًا يستحق الاهتمام..



