
من يتفوق في الأكواد والبرمجة؟ مقارنة بين نماذج الذكاء الاصطناعي
شهد مجال الذكاء الاصطناعي تطورات كبيرة خلال السنوات الأخيرة، وخاصة في مجال نماذج لغة البرمجة (LLMs).
ورغم أنها نقلة قوية في طريقة برمجة وتطوير البرمجيات، فقد نجد صعوبة في اختيار النموذج الذي يناسبنا. كما أننا نكون في حاجة لمعرفة المقارنات بينهم.
و في هذا المقال، سنحاول الإجابة عن هذا السؤال.
لكن دعونا الآن أولاً نتعرف على هذه الأدوات وكيفية عملها.
نماذج لغات البرمجة وكيف يولد الذكاء الاصطناعي الأكواد
تعتمد هذه الأدوات على تقنيات التعلم العميق، و بيتم تدريبها على كميات ضخمة من البيانات النصية، والتي تشمل في هذه الحالة أكوادًا برمجية بلغات مختلفة.
و من خلال هذه البيانات، تتعلم تلك الأدوات قواعد لغة البرمجة،و تكون قادرة على فهم تركيبها و توليد أكواد جديدة.
فعلى سبيل المثال، يمكنني أن أعطي له وصفًا لوظيفة برمجية، وسيقوم بإنشاء الكود الذي يعمل على تنفيذ هذه الوظيفة.
كما أننا نستخدمها في مجموعة متنوعة من المهام، مثل كتابة اختبارات الوحدات، وتحويل الأكواد بين لغات البرمجة المختلفة، وإصلاح الأخطاء البرمجية.
أمثلة على نماذج لغة البرمجة
هناك العديد من موديلات LLMs المتاحة حاليًا، منها:
GPT التابع لشركة OpenAI، و المعروف بقدرته على توليد نصوص وأكواد برمجية بنسبة نجاح و دقة عالية.
Claude من تطوير شركة Anthropic، و يعتبر واحد من أفضل البرامج على الساحة.
Llama من شركة Meta، و المعروف بقدرته على التكيف مع مهام مختلفة، مثل الترجمة وتلخيص النصوص.
و لكن تطور الذكاء الاصطناعي لم يتوقف عند هذا الحد، بل ظهرت فئة جديدة مع قدرات أكبر، و هي «نماذج التفكير الكبيرة» (LRMs) .
نماذج المنطق و التفكير الكبيرة (LRMs)
ظهرت مؤخرًا فئة جديدة من نماذج لغة البرمجة تُسمى نماذج الاستدلال الكبيرة (LRMs).
والتي تتميز بقدرتها على تنفيذ عمليات تفكير مُعقدة قبل توليد الأكواد البرمجية.
فعلى سبيل المثال، بدلاً من مجرد كتابة الكود بناءً على وصف وظيفة معينة، يأتي دور نماذج التفكير الكبيرة في تحليل هذه الوظيفة وفهم متطلباتها بشكل أعمق قبل البدء في تصميمه.
و هذا ما يؤدي إلى إنشاء أكواد أكثر دقة وكفاءة.
أنا أريد بناء منزل، فبدلاً من أن أبدأ مباشرةً في وضع الطوب، سأقوم أولاً بوضع خطة مفصلة أحدد فيها شكل المنزل، وعدد الغرف، ومكان كل غرفة. لأنني أعلم أن مجرد بدء وضع الطوب دون خطة قد يؤدي إلى أخطاء كثيرة.
تعمل LRMs بنفس الطريقة، حيث تفكر في المشكلة أولاً، ثم تضع خطة للحل، ثم تبدأ في كتابة التعليمات.
ولعل أبرز الأمثلة على LRMs هو نموذج «o1» (Strawberry) الذي طورته شركة OpenAI، والذي أظهر لنا قدرات عالية في حل المشاكل التي تحتاج إلى تفكير معقد، مثل تخطيط المهام وحل الألغاز.
الملخص
LLMs تركز على توليد الكود.
بينما تعمل LRMs على فهم المشكلة وحلها باستخدام التفكير المنطقي قبل إنشاء الأكواد.
هل اتضح الأمر لكم الآن؟
DevQualityEval: معيار لتقييم نماذج لغات البرمجة
كما أشرنا سابقًا أنه مع تزايد عدد نماذج الذكاء الاصطناعي، ظهرت الحاجة إلى معيار لتقييم أدائها و المقارنة بينها.
فكيف نستطيع فعل ذلك؟
DevQualityEval: أداة القياس
و هنا يأتي دور DevQualityEval، وهو معيار مفتوح المصدر طورته شركة symflower لتقييم أداء هذه الموديلات في مهام توليد الأكواد البرمجية.
حيث يُقدم هذا المعيار طريقة موضوعية لقياس جودة الأكواد التي تقوم بتوليدها، ومقارنة أدائها.
وفي الفقرات التالية، سنستعرض هذه الأمر بالتفصيل و كذلك نتائج DevQualityEval v0.6، وهو أحدث إصدار من المعيار.
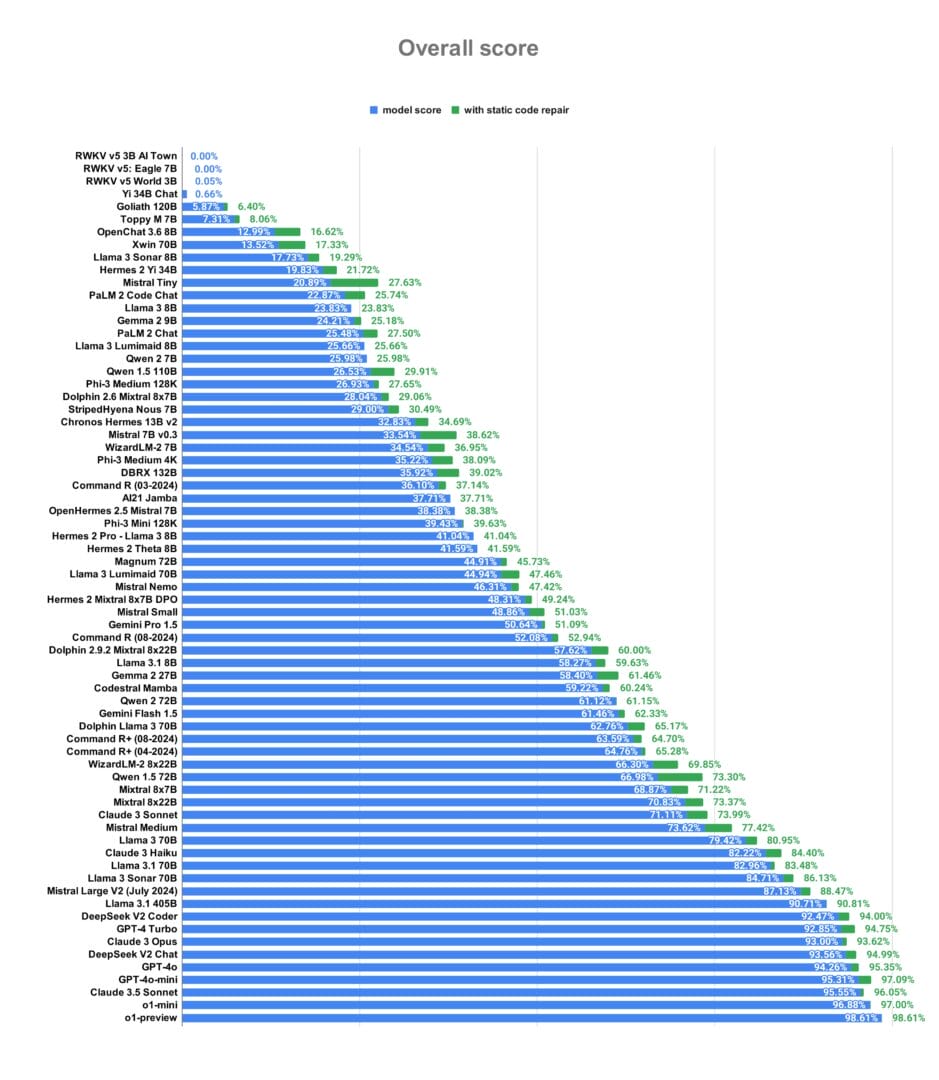
مهام DevQualityEval
يقيس DevQualityEval الأداء في مجموعة من المهام التي تُحاكي سيناريوهات تطوير البرمجيات المعروفة، مثل:
١. كتابة اختبارات الوحدات (Unit Tests): وهي اختبارات برمجية صغيرة للتحقق من صحة عمل وحدات محددة.
٢. تحويل الأكواد (Transpilation): وهي عملية تحويل كود برمجي مكتوب بلغة معينة إلى لغة أخرى، مع الحفاظ على وظيفة الكود.
٣. إصلاح الأخطاء (Code Repair): وهي عملية تحديد و معالجة الأخطاء في كود معين.
لغات البرمجة المدعومة
يقوم المعيار بتقييم أداء النماذج في لغات برمجة مختلفة، منها:
١. Go: لغة مفتوحة المصدر يتم استخدامها على نطاق واسع في تطوير تطبيقات الويب والأنظمة الخلفية.
٢. Java: وهي شائعة في برمجة تطبيقات سطح المكتب والهواتف.
٣. Ruby: ونستخدمها في تطوير تطبيقات الويب وواجهات المستخدم.
طريقة استخدام DevQualityEval
يُمكن استخدامه كتطبيق سطر أوامر (CLI) أو كحاوية Docker. حيث يقوم المعيار بتشغيل نماذج لغة البرمجة على مجموعة من المهام البرمجية، ثم يقيس أدائها بناءً على معايير محددة، مثل:
- صحة الكود و أن يكون خالى من الأخطاء.
- كفاءة التنفيذ: سرعة وكفاءة عمل الكود.
- الوضوح و سهولة قراءته وفهمه.
تفسير نتائج DevQualityEval
يقوم المعيار بعد ذلك بتقديم نتائج مُفصّلة عن أداء كل نموذج لغة في كل مهمة. و التي تساعدنا على فهم نقاط القوة والضعف في كل نموذج، واختيار النموذج الأنسب.
نتائج DevQualityEval v0.6: مقارنة نماذج الذكاء الاصطناعي
كشفت نتائج DevQualityEval v0.6 عن بعض النماذج التي أظهرت تفوقًا واضحًا في توليد الأكواد البرمجية، وذلك بناءً على معايير دقة هذه الأكواد، وكفاءتها، وقابلية قراءتها.
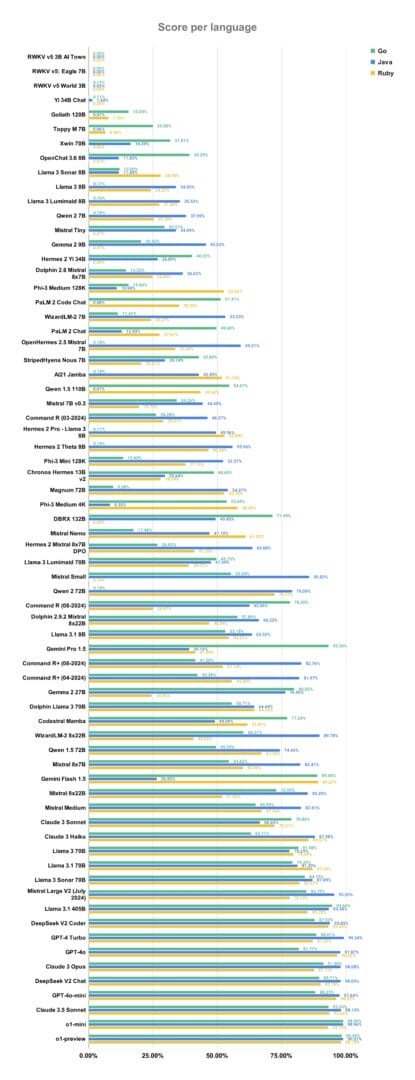
كما لاحظنا أن أفضل أداء يختلف من لغة برمجة لأخرى.
فعلى سبيل المثال، في لغة Ruby، كان نموذج o1-preview هو الأكثر تميزًا، حيث أظهر قدرته العالية على توليد أكواد Ruby دقيقة وفعّالة مع نسبة نجاح بلغت 98%.
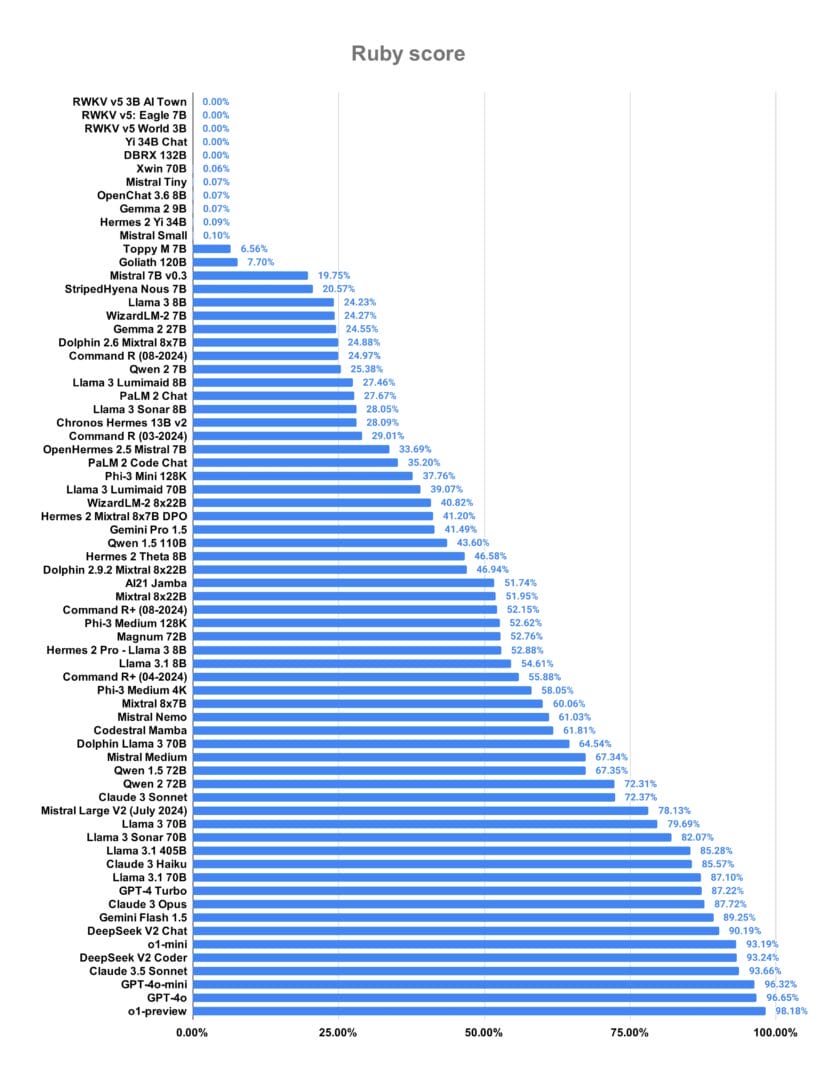
أما في لغة Go، فقد تفوقت نماذج o1 mini & preview في سرعة التوليد و كفاءتها بنسبة نجاح وصلت إلى 98%، ثم يأتي نموذج Llama 3.1 405B من شركة Meta في المركز الثالث بنسبة قاربت 95%.
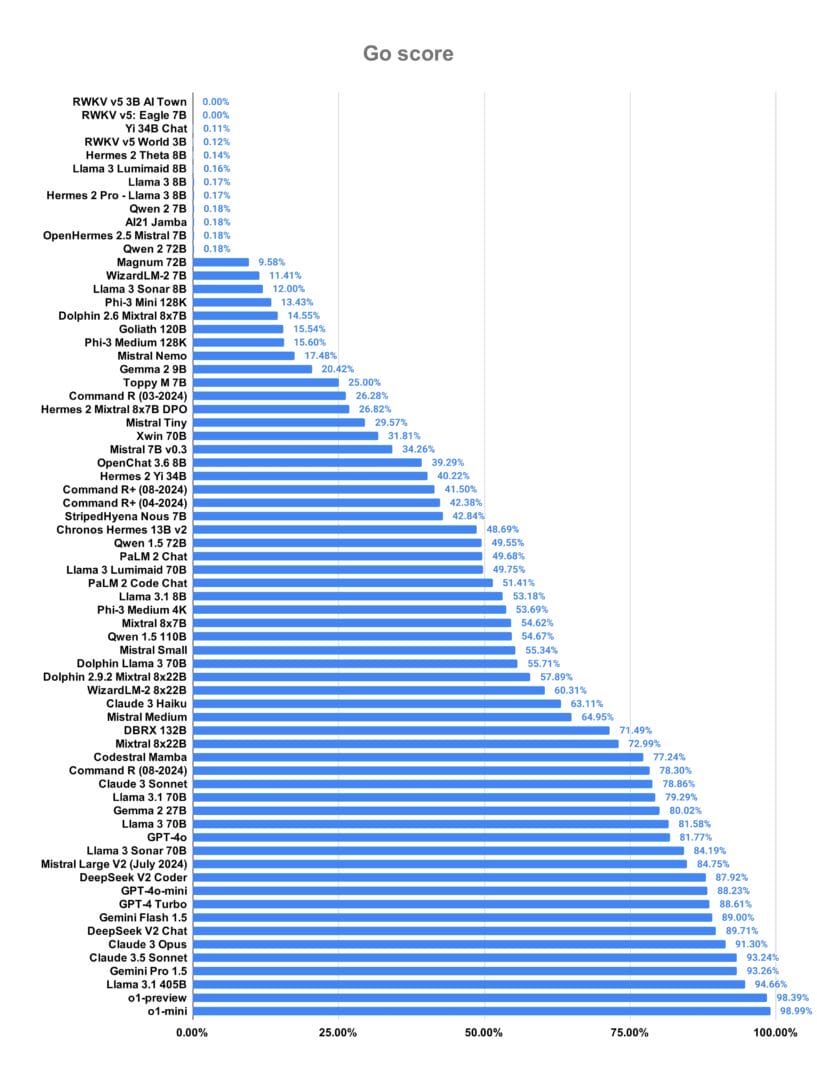
بينما في لغة Java، كان التنافس قويًا بين عدة نماذج، منها GPT-4 Turbo و o1 و Claude 3.5 Sonnet، و DeepSeek V2 Chat من DeepSeek. مع نسبة نجاح متساوية تجاوزت 98%.
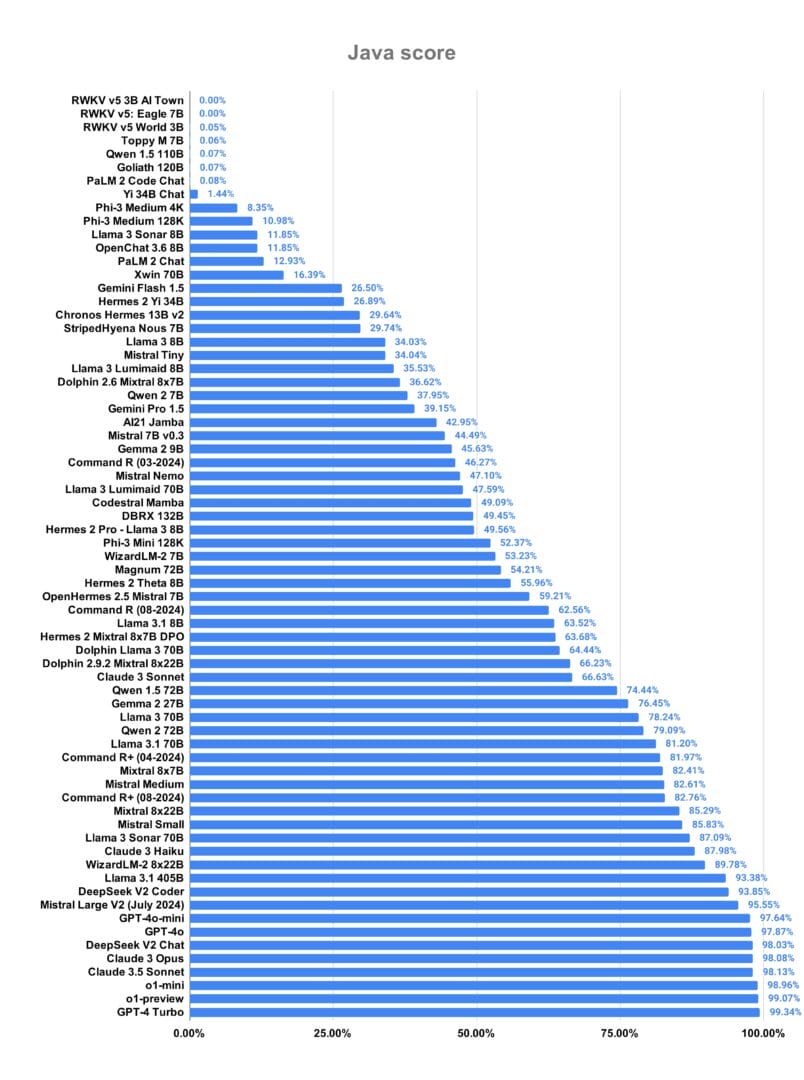
و وراء هذا التباين في أداء النماذج، هناك عدة عوامل لها تأثير بشكل مباشر على قدرتها على تصميم الأكواد.
و من بين هذه العوامل، يعتبر حجم النموذج من أهمها.
فكلما زاد حجم النموذج وزادت البيانات التي تم تدريبه عليها، زادت قدرته على فهم لغات البرمجة وتوليد أكواد أكثر دقة و كفاءة.
وكمثال على ذلك يعتبر نموذج Llama 3.1 405B من شركة Meta أحد أكبر النماذج حجمًا. وهو ما يُفسر لنا أداءه المُتميز في لغة Go.
و لكن، لا يقتصر الأمر على حجم النموذج فقط، فالتكلفة تلعب دورًا مُهمًا أيضًا.
فبعض النماذج تكون مُكلفة لاستخدامها، خاصة النماذج ذات الأداء العالي. و هذه التكلفة قد تكون عائقًا أمام الباحثين عن أدوات فعالة.
أما سرعة الاستجابة فهي عامل آخر يجب مراعاته. ففي بعض التطبيقات التي تتطلب تصميم الكود بشكل سريع، يكون وقت استجابة النموذج عاملًا حاسمًا.
ولتوضيح هذه العوامل بشكل أفضل، لنأخذ بعض الأمثلة.
فنموذج o1-preview من OpenAI على الرغم من دقته العالية في كتابة الكود، إلا أنه يُعاني من بطء في الاستجابة و تكلفة مرتفعة.
وهذا يعود بشكل ما إلى حجمه الكبير والعمليات المعقدة التي شرحناها سابقًا في فقرة LRMS.
في المقابل، نموذج Llama 3.1 405B من Meta أسرع و أقل تكلفة، لكنه قد لا يعطينا نفس مستوى الدقة في بعض الحالات.
و تجدر الإشارة إلى أن DevQualityEval في تطور مستمر، و يشهد كل إصدار جديد منه تحسينات وتغييرات مُهمة.
ففي الإصدار v0.6 على سبيل المثال، تم إضافة دعم لغة Ruby، مما سمح بتقييم أداء النماذج في هذه اللغة الشائعة.
و بالإضافة إلى ذلك، تم تضمين مهام جديدة في التقييم، مثل مهام إصلاح الأكواد، والتي لها دور في قياس قدرة النماذج على التعامل مع سيناريوهات برمجية أكثر واقعية.
كما شهد هذا الإصدار أيضًا تحسينات في واجهة المستخدم، ليصبح من السهل على المطورين استخدام المعيار وتفسير نتائجه.
كيفية اختيار نموذج لغة البرمجة المناسب لك
بعد أن استعرضنا نتائج DevQualityEval v0.6 وتعرفنا على أداء نماذج لغة البرمجة (LLMs) المختلفة، دعني أطرح عليك السؤال التالي: كيف يُمكنك اختيار النموذج الأنسب لاحتياجاتك؟
العوامل التي يجب عليك مراعاتها
عند اختيار نموذج لغة برمجة، يجب عليك مراعاة عدة عوامل، منها:
١ نوع المشروع: حيث تختلف متطلبات المشاريع البرمجية.
فعلى سبيل المثال، قد يتطلب مشروع تطوير تطبيق ويب نموذجًا قادرًا على توليد أكواد JavaScript و HTML، بينما قد يتطلب مشروع تحليل البيانات نموذجًا قادرًا على التعامل مع لغة Python.
٢. لغة البرمجة و الأداء: فكما رأينا بالمقارنات السابقة أن بعض الأدوات تقدم أداءً أفضل من غيرها حسب نوع اللغة.
لذا تأكد من أن النموذج الذي تختاره مناسب للغة البرمجة التي تستخدمها في مشروعك.
٣. الميزانية: تختلف تكلفة استخدام هذهِ النماذج من شركة لأخرى. و بالتالي حدد ميزانيتك واختر نموذجًا يتناسب معها.
٤. سهولة الاستخدام، حيث تختلف واجهات برمجة التطبيقات (APIs) للبرامج. و لهذا قم باختيار النموذج الذي يُوفر لك واجهة برمجة سهلة الاستخدام.
كما أنصحك أن تجرّب النماذج بنفسك.
نعم، قياسات الاداء و قراءة المراجعات شئ هام للغاية، و لكن التجربة في رأيي عامل مهم أيضًا.
و العديد من الشركات التي نماذجها مدفوعة تقدم إصدارات تجريبية منها. جرّب هذه الإصدارات لاختبار أداء النماذج وتحديد ما إذا كانت تناسب احتياجاتك.
أو استخدم النماذج مفتوحة المصدر كحل آخر مثل Llama، و الذي يبقي واحدًا من أفضل هذه النماذج.
و تذكر دائمًا أنه لا يوجد نموذج لغة برمجة واحد يُناسب جميع الاحتياجات. و لهذا يجب عليك اختيار النموذج الذي يتوافق مع متطلبات مشروعك ويتناسب مع ميزانيتك ومستوى خبرتك.
اطلع أيضًا على أحد مقارنات نماذج الذكاء الاصطناعي في حل الالغاز الرياضية.



